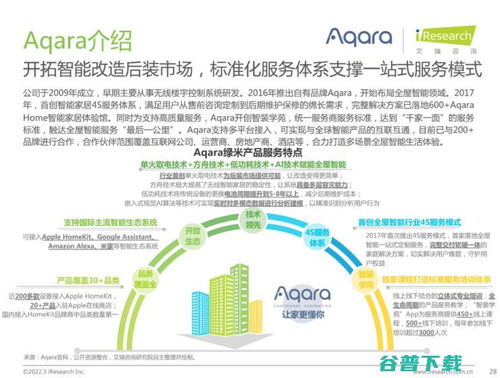
物理層與網絡技術服務 計算機網絡微課堂筆記解析
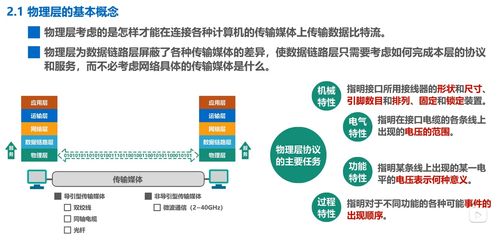
在湖南科技大學計算機網絡微課堂的深入學習中,物理層作為OSI參考模型的最底層,是連接數字世界與真實物理世界的橋梁。它不僅定義了數據傳輸的物理媒介特性,還直接支撐著上層各類網絡技術服務的實現。
一、物理層的核心功能
物理層的主要職責是在一條通信信道上傳輸原始比特流。它不關心數據的含義或結構,只關注如何利用物理介質(如雙絞線、光纖、無線電波)實現可靠有效的信號傳輸。這包括:
- 信號編碼與調制:將數字數據轉換為適合在物理媒介上傳播的電信號、光信號或電磁波。
- 傳輸媒介管理:定義接口的機械、電氣、功能和規程特性,例如網線接口的形狀、電壓大小、信號線功能定義等。
- 比特同步:確保發送端和接收端能以相同的節奏識別每個比特的起止。
二、物理媒介與技術服務的基礎
不同的物理媒介支撐著不同特點的網絡服務:
- 雙絞線(如以太網線):普遍用于局域網(LAN)接入,成本低,安裝簡便,是校園網、企業辦公網絡服務的物理基石。
- 光纖:以其高帶寬、低損耗、抗干擾強的特性,成為城域網(MAN)和廣域網(WAN)骨干、以及高速互聯網接入(如光纖到戶)的核心媒介。
- 無線電磁波(Wi-Fi、蜂窩網絡):實現了移動性和靈活接入,是移動互聯網服務(如4G/5G)和無線局域網絡服務的物理承載。
三、從物理層到網絡技術服務
物理層的穩定與高效,是上層所有網絡技術服務(如網頁瀏覽、視頻流、云計算、物聯網)得以實現的根本保障。例如:
- 高速互聯網接入:依賴于光纖到樓/戶(FTTx)的物理層部署。
- 數據中心內部互聯:依賴高速光纖和專用電纜實現服務器間海量數據的低延遲交換。
- 移動支付、即時通訊:其即時性和可靠性,底層依賴于蜂窩網絡或Wi-Fi物理鏈路的信號質量和覆蓋。
四、
理解物理層,就是理解網絡世界的“地基”。它雖然不直接處理復雜的應用數據,但它定義的速度、距離、可靠性和抗干擾能力,從根本上框定了網絡技術服務的性能上限與發展方向。在數字化時代,無論是規劃一個校園網絡,還是部署新一代的5G或全光網絡,扎實的物理層知識都是進行設計、排障和優化的關鍵起點。
如若轉載,請注明出處:http://www.mtripair.cn/product/35.html
更新時間:2026-03-09 06:29:34